
Voice Forensics
The following is a summary of the work done by my team at the CMU IPTSE Winter School 2014.
</br>
OBJECTIVE
To build a
voice forensics system that would identify bodily features such as height,
weight, age, sex, region of origin and various other demographic information
about a miscreant from the voice evidence collected. The end objective is to
build an extensive, if not comprehensive, one-of-a-kind voice print database to
enable authorities to track criminals.
ABSTRACT
Security
has become a great concern for the citizens of our nation. With incidents such
as bomb attacks, ransom calls, and threat calls to life and property occurring
more frequently, it is important to develop a mechanism to help curb them. It
is vital for the government to devise a mechanism to deal with threats and
ransom calls in an effective and promising way. Voice Forensics has potential to
help the law enforcement agencies by providing valuable information such as
height, weight, age, sex of the suspect from the voice evidence available. In
the current scenario of crime investigation in India, we are technologically
ill-equipped to investigate cases that have only audio as their evidence. Our
project tries to solve this problem. Through this project we wish to explore
and improvise the area of Voice Forensics. The ultimate aim of the project is
to equip law enforcement agencies with the tools to process voice samples and
provide physical and demographic information about the miscreant that could be
used as an important evidence for investigation purposes. We propose to build a
unique one-of-a-kind voice print database for further research and analysis.
INTRODUCTION
During the
process of criminal investigations, it is imperative to extract as much
information as possible from the available evidences. Currently, the National
Crime Records Bureau cites two methods of Criminal identification, one using
fingerprints, and the other is a portrait building system. Fingerprint matching
could provide accurate information about the criminal, but in cases where
evidence is not available, or if the person is not recorded in the database, we
will not be able to make any predictions. In case of fingerprints, it is
impossible to approximate predictions about the person, if he/she is not
recorded in the database. Presently, there are 11 divisions under the CBI for
forensics and crime investigations in India. Surprisingly, voice forensics is
not one of them yet. With the technology we are developing, it would be
possible for the CBI to investigate cases with the evidences obtained from
voice and speech also. With this
tool, voice could be used as a reliable evidence in a court proceeding as per
Section 65B of the Indian Evidence Act, 1972.
Exploration
of voice as a possible evidence is quite recent, and there are some advanced
voice identification software’s being developed, such as VoiceGrid. While,
voice based technologies such as Siri and Cortana are used as personal digital
assistants in mobile phones, VoiceGrid is a database intensive tool that has
been adopted by various state police organizations in the USA and Russia for
identification of miscreants based on the voice sample captured. These systems
rely largely on an existing database to make exact or close-to matches.
However, in cases when the exact voice samples cannot be matched, or is
unavailable in the database, it is very useful to extract physical and
geographical information of the miscreant from the voice sample available.
Hence, there is scope to develop much smarter and efficient systems for the
purpose of voice forensic study. In addition to this problem, there are no
publicly available benchmarks to test an attribute identification method. This
is mainly due to the difficulty in procuring a large dataset for the models to
work on and the absence of a framework for testing. Moreover, there exists no
framework that does the work of:
1. Collecting
a large quantity of audio data from the citizens of our nation
2. Storing,
Analyzing, Validating the audio samples collected and managing it securely.
3. Perform
formal research on the collected voice samples. There is no framework that
allows for testing different models that predict physical attribute of a person
from their voice.
4. Provides
aids to the work of researchers across the country to use this nationwide audio
database for other interesting applications. (Anonymity of persons will be maintained
for security purposes).
Within this
project, we propose to build a framework that would solve these problems. We
aim to build the necessary technology for voice forensics and investigation.
The long term aim of this project is to equip law enforcement agencies with the
required tools to perform voice forensics and provide necessary evidence for
enforcement of law and order. With the system we build, the officials should be
able to estimate with good accuracy, the physical and geographical features of
the suspect.
DATA COLLECTION
Voice
samples were collected from 40 students who participated in the IPTSE CMU-NITK
Winter School 2014. The age group of the participants was in the range of 19-22
years. The height, weight, age and sex of the students were recorded. Each
student was asked to speak a set of 25 phonetically rich sentences randomly
selected from the large TIMIT database. Thus, there were 25 recordings per
person, making a total of 1000 recordings. The samples were recorded using an
external microphone on Audacity, in a relatively quiet room. We ensured that
the recordings were lossless. All other necessary conditions like distance
between the speaker and the microphone were taken care of while recording the
voice samples.
METHODOLOGY
The
Framework we are developing consists of machine learning tools, classification
and regression algorithms that extract and analyze features of the voice and
learn the correlations of the physical features and voice of the speaker. The
framework depicts the pipeline of computations and analysis. The pipeline
mainly consists of the following:
1. Feature
Extraction
2. Normalization
of data
3. Clustering
(Bag of Words Model)
4. Machine
Learning Algorithms
Ø Classifier
Models
Ø Regression
Models
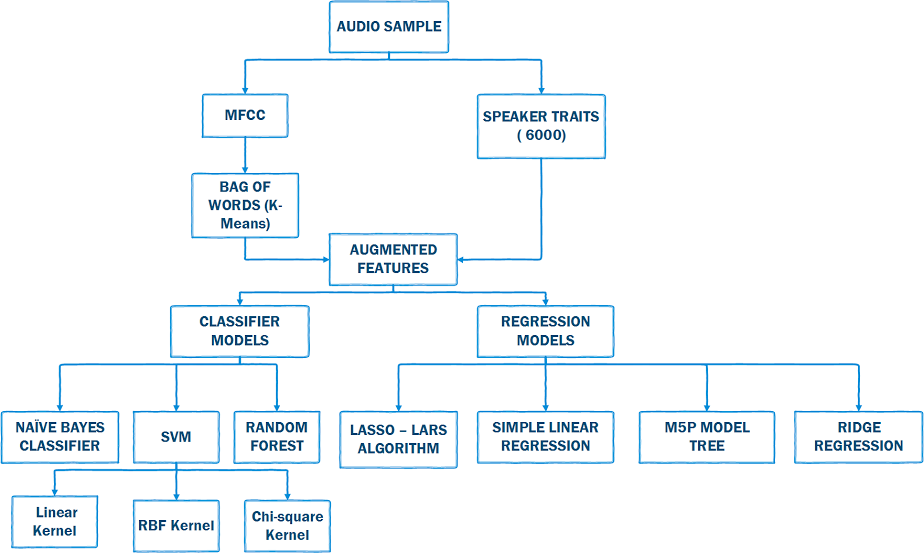
The
pipeline followed is depicted in the picture demonstrated above.
The following sections will explain the above sections in detail.
RESULTS
The initial results that we obtained was itself a
proof of concept for what we were trying to build. Given that the data set we used to test our system was
meagre and biased (male-female ratio was 3:1), we were still able to generate
results with good accuracy. We could predict the gender of an unknown person’s
voice with an accuracy of 95.2% and predict his/her height with an error of
6.5cm. With more data, and fine-tuning, our system could become reliable enough
to finally reach our desired goals.

WEBSITE
To make our tool publicly usable,
we have developed a website. The website allows a user to upload a voice sample
(only .wav files are accepted as of now) and outputs the physical
characteristics of the owner of that voice in the sample. To predict the
physical features, the voice sample inputed is run on the already trained model.
In future, we intend to make a provision for users to contribute training data
as well. To ensure authenticity and security, only validated users shall be
allowed to upload their voice samples and their physical characteristics. After
inspection of the samples collected from the website for genuineness, it will
be used for training of our models.
FURTHER WORK
●
LASSO regression for height estimation,
●
Augmenting 6000 features(speaker traits) with bags of words
features,
●
Since we have got high accuracy for gender classification, we
would now hope to see better results by using the predicted gender itself as a
feature for height prediction.
●
The data collected was biased, we had a girls to boys
ratio of 1:3. We need to test our models on a larger data set with unbiased
inputs and check for the performance.
ACKNOWLEDGMENT
We would like to extend our gratitude to our guides Prof
Bhiksha Raj, Prof Rita Singh from CMU and Mr. Pulkit Agrawal, PhD student from
University of California, Berkeley. A special thanks to the entire IPTSE Winter
School Team for providing us the opportunity and resources to work on this
project.
POSTER
.png)
POSTER
Team Voice Forensics:
1. Tejeswini Sundaram, BTech Computer Science, MIT Manipal
2. Priya Soundararajan, Int. M.Sc. Applied Mathematics, IIT
Roorkee
3. Utkarsh Patange, BTech Computer Science, IIT Kanpur
4. Sakthivel Sivaraman, BTech Mechanical Engineering, NITK
Surathkal

Written on October 20, 2015